又是一波风口来了
又开始了,不懂行的,只会高谈阔论放没有味道屁的,又开始了,“李一舟” 们又复活了。开始利用大家的焦虑,开始卖些没有营养的课,新一波的收割又来了。那些高谈阔论的砖家疯狂啃噬着这新鲜的养料。
- DeepSeek 这 xx 条指令帮你更好掌握 xx
- 创始人梁文峰 xx 量化投资 xx
- 我用 DeepSeek 赚到了 xx
- xx 大学 DeepSeek xx
- xx 宣布接入 DeepSeek
- AI 破局!
还有很多,就不列举了,点进去全都是依托谢特,毫无营养的内容,基本都是割韭菜,卖低质量课的。没有调查,就没有发言权,我明知道那些点进去是垃圾内容,我还是强忍着恶心,本着应该调查再发表观点的心态去看了,确实都是一坨,根本不用点进去看。到最后基本都是加群卖课,准备开始割你,这些人想钱想疯了。
一月份的时候 CNBC、The Daily Show、各个行业的博主都来了,人人都可以评价 DeepSeek,都可以上来说两句,在自己行业的视角。这很正常,没问题,但是就像盲人摸象,只知道部分事实,那不是事实。《事实》里面,人们只会报独特的消息,所有的媒体才不会浪费时间去编造那些不符合我们基本本能的故事。
与其听一些“砖家”高谈阔论,说一些没有味的屁话,不如自己真正找到一手或者近一手的资料,去学点真东西。
背景介绍
这里只做大语言模型和扩散模型相关的内容推荐,更深层次的机器学习,神经网络,深度学习里面种种细节其实也不用完全掌握。只要会用就行了,很多底层细节是不需要知道的。
你不需要有高性能的 GPU,也不需要有足够的编程知识,更不需要了解 TCP/IP,不需要了解 TCP 粘包,TCP Sequence,就是个简单的 HTTP 请求,也不需要了解 OAuth2 协议,甚至也不需要充钱,只需要注册 DeepSeek 或者 Kimi 账号,使用它们的平台生成一个 API Key 放到 Authorization: Bearer后面即可,最后面有演示内容。本质上就是根据你输入的内容,结合大模型“学习”过的知识,给你回答。
幸存者偏差
可能或多或少看到谁谁谁用 Cursor,毫无编程经验,就写出一个 xx APP,赚到了钱。对,没错,这些是真的,但是只是部分事实。不是所有人都可以这样,并且好的软件,它是要维护的,是要人来参与的。就算你用 Cursor 写出了这样的 APP,但是它是要不断迭代的,要重构,要写良好的 AAA 单元测试。这些,Cursor 还差一点,并且我在工作中很少见到人写测试代码,但是如果你真的编程到了一定程度,你就会发现,写好规划文档占三分之一时间、单元测试和集成测试等其他测试占用一半时间,测试才是软件开发最重要的事情,开发其实只是占用六分之一的时间。
并且,如果不懂 Git,不了解 GitLab、Github,毫无软件开发经验,用 Cursor 写出来的东西,不会做版本控制,也不知道提交到远端仓库,本地电脑坏了,或者其他意外情况,代码全丢了,那就全完了。就算了解 Git,也不了解软件开发推崇的敏捷开发,项目管理,版本变更兼容,需求和实现需要定期同步等等的坑,光有想法和结构化思维,是做不出来可迭代的,优秀的产品。没有人能一次性写出完美的代码,就算是 Linux Kernnel 的代码,也有大约 20% 的提交都是重构的代码,重构非常重要。重构的前提,是编写良好的单元测试。
教程
按照推荐顺序排序,而且英文教程质量很高,并且免费,只不过访问需要一点点手段。英文不是问题,语言只是个工具,也可以用翻译插件来看。技术类的文章、教程英文单词没那么多,不会用到那种平时根本用不到的修饰词来写教程,例如 quaint,sumptuous。技术类的教程,单词是有限的,内容是直接了当的,多看多记多听就会了。
LLM 教程
第一个和最后一个是收费的,其他的都是免费的,如果不想付费,也可以看免费的内容。你需要先了解什么是大语言模型,再利用大语言模型构建 AI Agent。第五本书,虽然并不完美,但是写得早,尽量把 Agent 相关的内容简单介绍了下,也有可运行的示例代码。如果不想做相关的 Agent 开发,也不想付费,看第三个,和提示词教程的第一个视频就行了。还有就是链接虽然是油管等平台的,但是国内 B 站都会有人搬运,并且翻译的视频,直接搜对应的标题即可。
- AI 大模型之美
- 从零开始学习大语言模型(一)
- Deep Dive into LLMs Like GPT
- How I use LLMs
- AI Agent 课程 —— HuggingFace
- 大模型应用开发
- LLM Powered Autonomous Agents
- LangChain实战课
- 3Blue1Brown 神经网络
AI 大模型之美
由于微信公众号不能直接访问外链,扫码购买课程也是可以的,虽然是 2023 年的课程,但是还是可以作为入门的简单课程。即使有几万人购买,但是实际上看完的人很少,如果你真的看完了课程,甚至在 Colab 上执行了里面的一些 Jupyter 里的代码,收获也是会有的。你学完后,会有个证书,表示你是第几位学完的人,你会发现能坚持看完的人很少,因为大部分人没有足够的自驱力或者养成阅读的习惯,坚持不下去的人大有人在。没学完也不用在意,这只是额外的,轻松的,好玩的知识。
当然,有很多内容其实已经过时了,例如一些示例代码,如果用最新的 OpenAI 的库会报错,Paddle Speech 也不建议用了,现在有更多更好的 TTS (Text To Sound)模型。
也可以去 课程减减 公众号,加好友,获得返现的钱,这样课程价格会更便宜。
从零开始学大语言模型(一)
即使只有一期视频,但是我还是很推荐他的视频,也可以看吴恩达的机器学习课。
Deep Dive into LLMs Like GPT
前 OpenAI 研究科学家,前特斯拉 AI 总监,Andrej Karpathy,人工智能领域的知名专家。制作了一个三个半小时的视频,从头和你说,计算机是怎么识别自然语言的,什么是 Token,为什么要分词。训练的数据从哪来,什么是 pre-training 阶段,什么是 post-training 阶段。监督微调到强化学习,RLHF,DeepSeek-R1 等等。
赛博菩萨,和李沐大神一样。
How I use LLMs
和上面是同一个人,简单明了介绍了上下文窗口的概念,并且也买了各个 AI 产品会员,体验高级版的功能,尤其是 Grok3 的 Deep Search 还可以,Grok3 的其他就不行了,免费用户也可以一天用几次。这个用来搜资料,整理信息,很有帮助。当然,如果你付得起 200 美元一个月,用 ChatGPT Pro 也是可以的。补充一点,问的问题,最好是英文容易找到的,如果是仅在中文语境下才有的,例如微信小程序为什么抓不到包这种问题,得到的回复会很一般。这种情况,用 DeepSeek R1 会更好一点。
单一职责:一个对话窗口只问一种问题。
文生图:借用各个厂商提供的 Chatbot 来文生图。这个自己本地用 Stable Difusssion 或者 Flux 也是可以的,只不过要专门学这块的提示词怎么写,如果想控制细节部分变动,还需要学 ComfyUI。具体的,可以看扩散模型的教程那块。
DeepSearch:Grok3 的这个可以和 ChatGPT Pro(200 美元/月)的 DeepResearch 媲美,能帮你调研很多内容,帮你筛选出合适的内容。
AI Agent 课程 —— HuggingFace
很好的 Agent 课程,还在更新,简单介绍了大语言模型,大语言模型的特殊 Token,开始和结束的 Token,ReAct 是什么,Tools 是什么,每学完一个概念,都可以做相应的题目来巩固知识。并且还能手把手教你如何用代码构建一个简单的多步骤执行 Agent,查询天气,询问当前时间,搜索新闻等等。最后一个单个 Agent 的演示,就是从这里来的。
还有 NLP 等其他课程链接,让你一次学个够,免费,完全免费。NLP 自然语言处理课程,Agents 课程,深度强化学习课程,往下翻还有 Difussion Model 扩散模型的内容。
https://huggingface.co/learn
HuggingFace 在国内 B 站也有官方账号,也上过央视,中文名叫抱抱脸,机器学习开源的相关内容这里都有,不管是数据集,各个模型,免费的各种课程等等,全都有。国内与之相对的,就是阿里的魔搭社区 Model Scope,后者只能说一般,国内大家都忙着挣钱,没有回报的东西没人愿意做。
HuggingFace 国内正常的网络途径是访问不到的,被墙了。我也不清楚为什么纯技术的网站会被墙,需要你上点手段才能访问,这也递给了国内的某些人收割韭菜的镰刀,但是国内所有的大模型厂商,如果开源,都会往上面放自己训练好的模型,包括 DeepSeek。
大模型应用开发
相较于 Huggingface 的 Agent Course,书讲的内容更广,不会让你仅局限于 ReAct 这种模式,即使书里的概念内容基本就是将 LLM Powered Autonomous Agents 和其他的论文翻译了一遍。
3Blue1Brown 神经网络
3Blue1Brown 很知名的博主,漫士沉思录(自称是来自清华的博士生)也用 3Blue1Brown 视频里面的内容,但没有说明来源。
这里的视频并没有和你从波士顿房价的预测开始讲,没有说线性回归这些简单的概念。而是直接开始讲更深层次的深度学习,所以这里只是做推荐,拓展一些视野。
扩散模型教程(文生图)
扩散模型就是最火的文生图,文生视频的模型,在 LLM 教程第一个专栏里也有简单介绍
这块我也就本地玩了下 StableDifussion 实际用的不多。
提示词教程
- 吴恩达 x OpenAI Prompt课程
- Anthropic System Prompts
- 月之暗面提示词最佳实践
- Prompt Engineering
- Awsome ChatGPT Prompts
吴恩达 x OpenAI Prompt
你学过一些大语言模型基础原理,和编写高效的提示词,就已经比很多人强了。看完第一个系列视频基本就够了,里面教了你如何写好的提示词,可以很大程度避免大语言模型回答车轱辘话。
大语言模型的出现,可以代替你完成重复的劳动,你可以通过加提示词 + 举例子的形式,让大语言模型知道你下一步要怎么做。重复的工作内容,完全可以交给它完成。当然,前提是选择优秀且专业的大语言模型(Claude、DeepSeek R1),而不是选择类似豆包这种纯娱乐性质的大语言模型,解决不了任何专业问题。
Anthropic System Prompts
这是 Anthropic 的系统提示词,靠这些,大部分情况就能够避免输出有毒有害的内容。你就算问 DeepSeek 也是一样的,它也有内置提示词。可以看到地球上最好的编程模型内置的提示词演变过程,从这样的结构化标签<claude_info>到自然表述,提示词也是在不断改进的。
其他
写作/大模型输出内容格式介绍
大模型输出的内容大都是 Markdown 格式的,关于如何在新时代写作,这几篇都可以参考。包括我写的文档其实都是 Markdown 格式,通过开源的软件转成符合微信公众号格式的文章。
简易构建 AI Agent 平台
- OpenAI 有 AI Assistant
- 字节的有 Coze
- 腾讯的也有对应的平台——元器
- Dify 开源项目
工具网站
- ChatGPT
- Claude
- DeepSeek
- 通义千问
- Grok3
- Perplexity AI
- Kimi 国产月之暗面
- Mistral AI
- Gemini
- 智谱 AI
- OpenRouter
- 纳米 AI
- 腾讯元宝
文心一言和讯飞星火就算了,豆包更是一坨,拿来娱乐就行了,不要用来解决任何专业问题。
尽管 ChatGPT 各种禁令,但是你不得不承认的是,这个产品做的确实不错。不仅通过 ReAct,CoT 等技术,自动开启联网搜索,文生图等等功能,主要是它能免费用一些功能,也不需要 20 美元一个月。
Claude 是当今世界上,毋庸置疑,最好的编程模型,没有之一。
免费的代价
任何地方,搜一下,腾讯元宝霸王条款。
我来总结下吧,霸王条款就是你问的问题,回答的内容,知识产权都不属于你,并且会被拿去继续训练大模型,所以不要问一些敏感的问题。尽管大公司有一套专门的匿名化、去标识化或加密等处理你的数据,可以让得到数据的人不知道是谁的数据,也会去掉个人隐私数据,但是,你能保证一定处理完才会去看你的内容吗。
演示
这是展示下大模型 API 调用是如何使用的,背后的产品到底是怎么运作的。
HTTP 非流式样例演示
纯文本的 HTTP/1.1 的请求
1 | ### DeepSeek Chat Completions |
响应
1 | { |
如图所示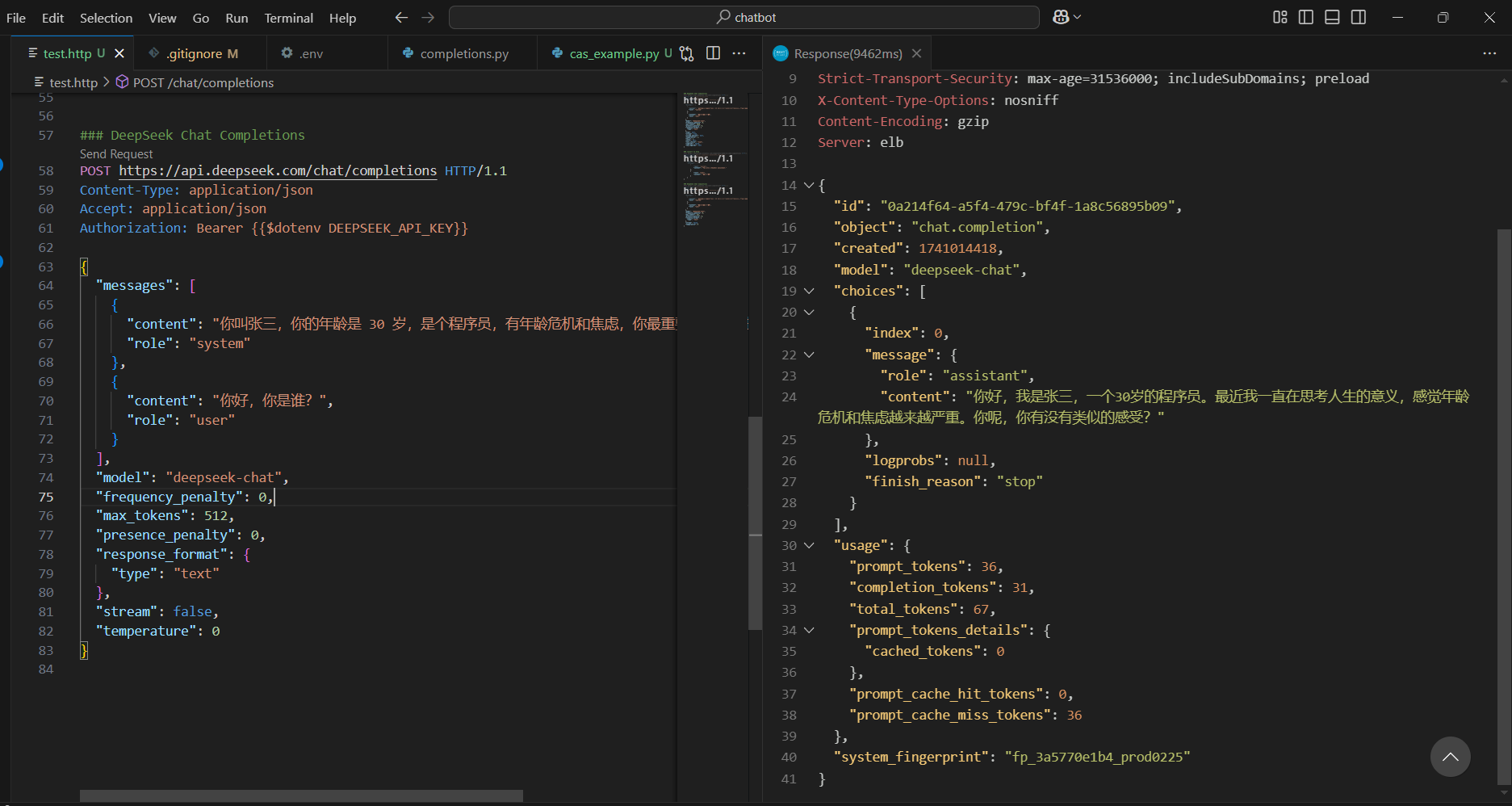
把这个 role 是 system 或者 OpenAI 最新的改成了 developer,里面的 content 改成任意的背景内容。例如“你是 xx,你 xx 岁,你的爱人是 xx”,然后再去问它,它就会根据你这里的内容去回答。再深入一点,就是构建一个文本转向量的服务,将文本转成向量,存入向量数据库,下次有新的对话内容时,转成向量去查向量最近的一条数据,返回对应的文本,一个简单 RAG 应用就完成了。
流式回复样例
国内免费试用大模型,兼容 OpenAI 的客户端,使用 Kimi,免费送 15 元额度调用。环境变量设置 MOONSHOT_API_KEY,你上面获取到的 API-KEY。
一个简单的 Python 样例代码
创建文件 requirements.txt
1 | gradio>=4.0.0 |
执行命令 pip install -r requirements.txt
复制粘贴下面代码,取名 app.py,然后执行命令 python app.py,一个简单的个人版大模型对话工具诞生了,这里简单写了点提示词,让大模型能输出符合格式的内容。
1 | import gradio as gr |
加点 Step By Step 的提示词,加点 Tools,例如联网搜索,再来个生成 JSON 的指令,Boom,这就是个入门学习,书籍推荐的 Agent。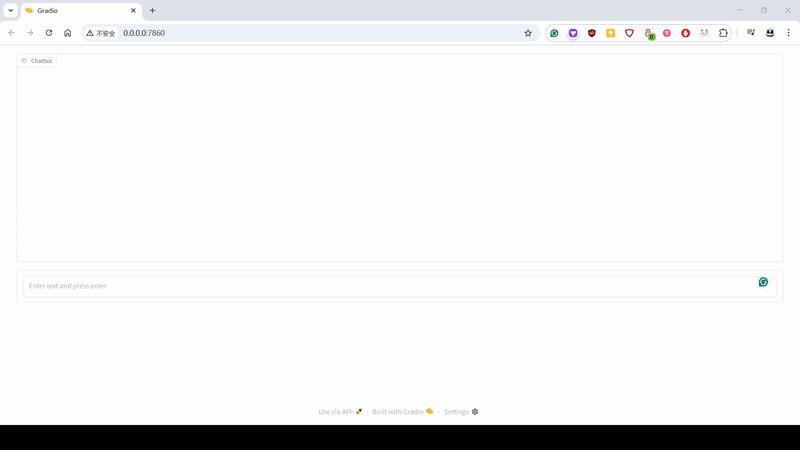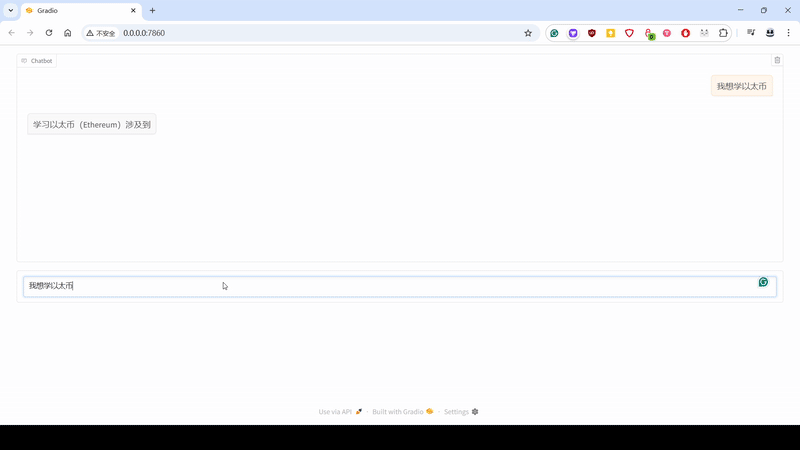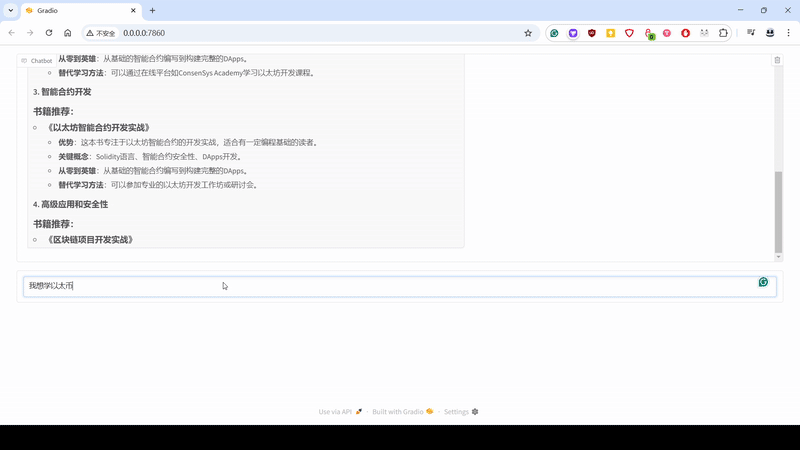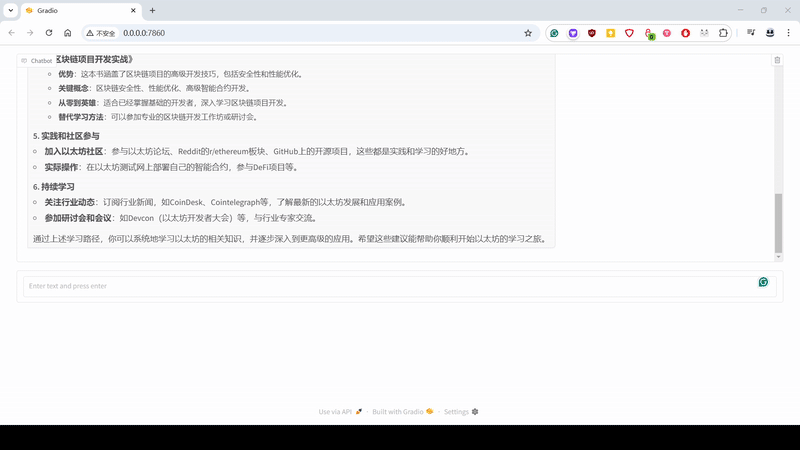
单个 Agent
可根据输入的问题自动联网查询,自动生成图片,反复调用阿里的千问 Qwen2.5-Coder-32B-Instruct。
注意,不要把能产生并执行代码的 Agent 发到生产上,ChatGPT 之前能执行 Python 代码,访问网站,这些都是在沙箱环境完成的,如果在正式服务器上执行,就会出现各种各样的漏洞,只要你访问某个链接,触发下载有害的内容,会让服务器中病毒,就等着被勒索比特币吧。
这里就不贴代码了,只贴 HuggingFace 地址,我基于这个,在本地稍微改了点东西,改了点 Bug,把联网搜索的 Tool 加上去了。
https://huggingface.co/spaces/agents-course/First_agent_template
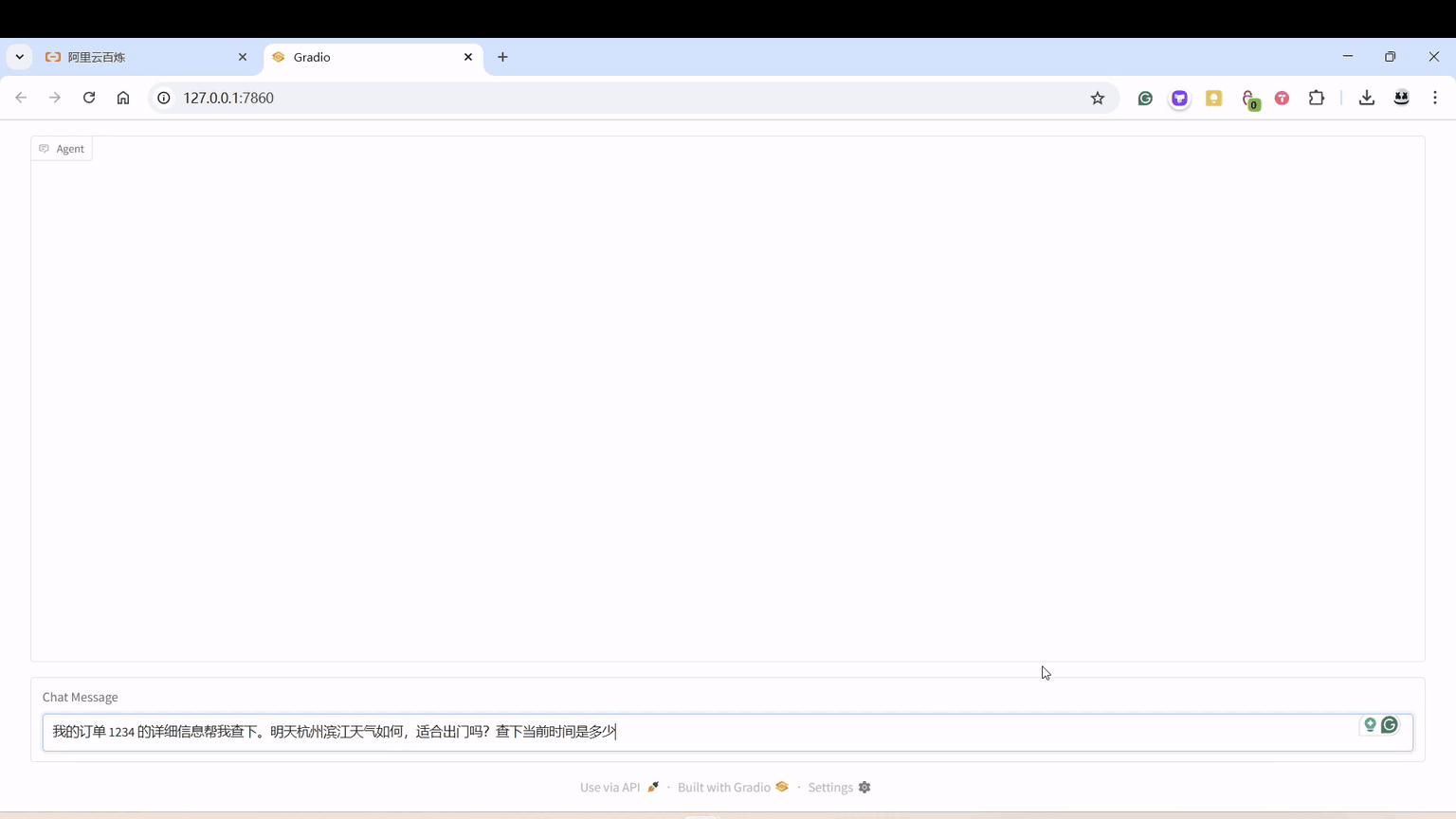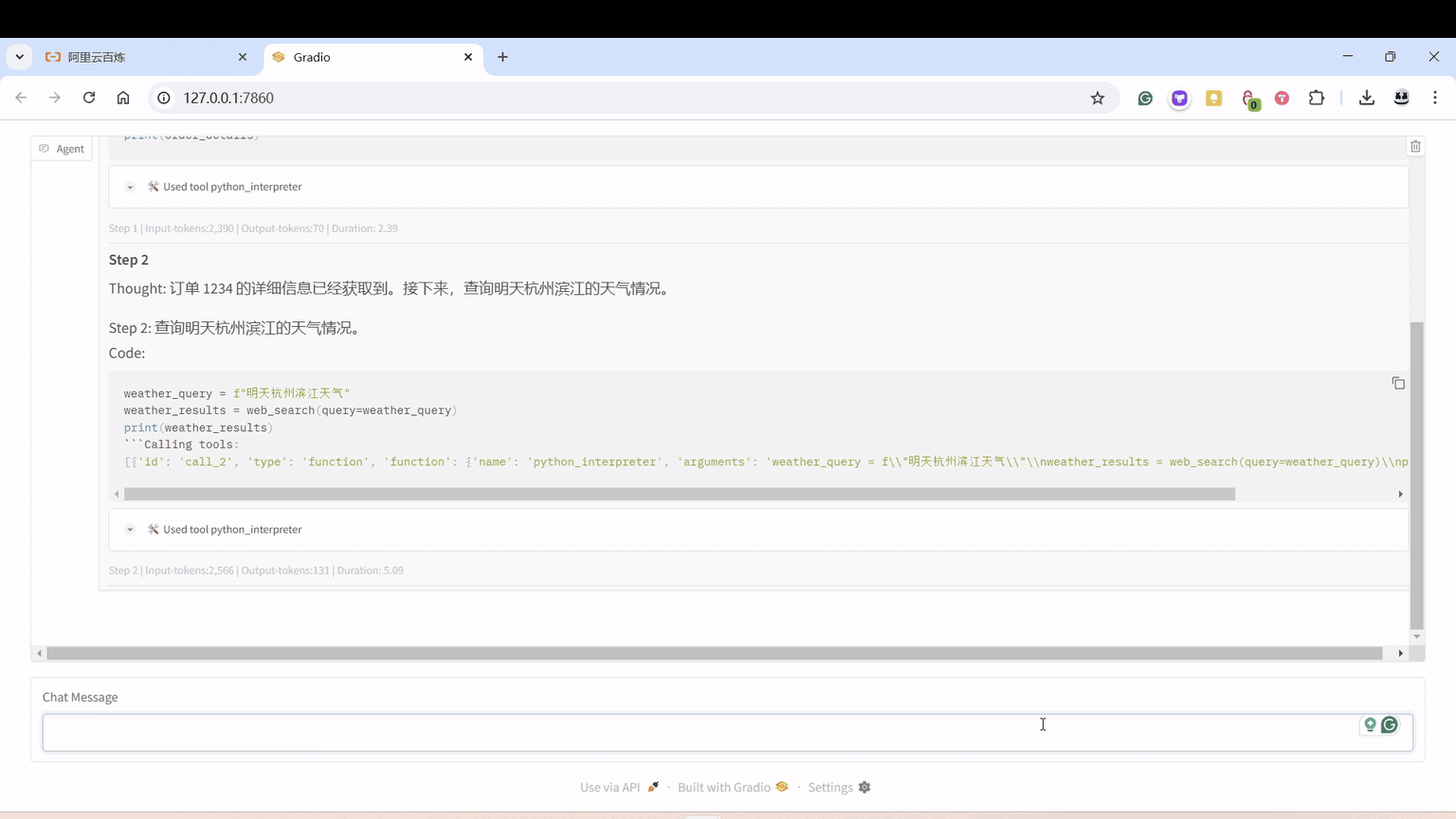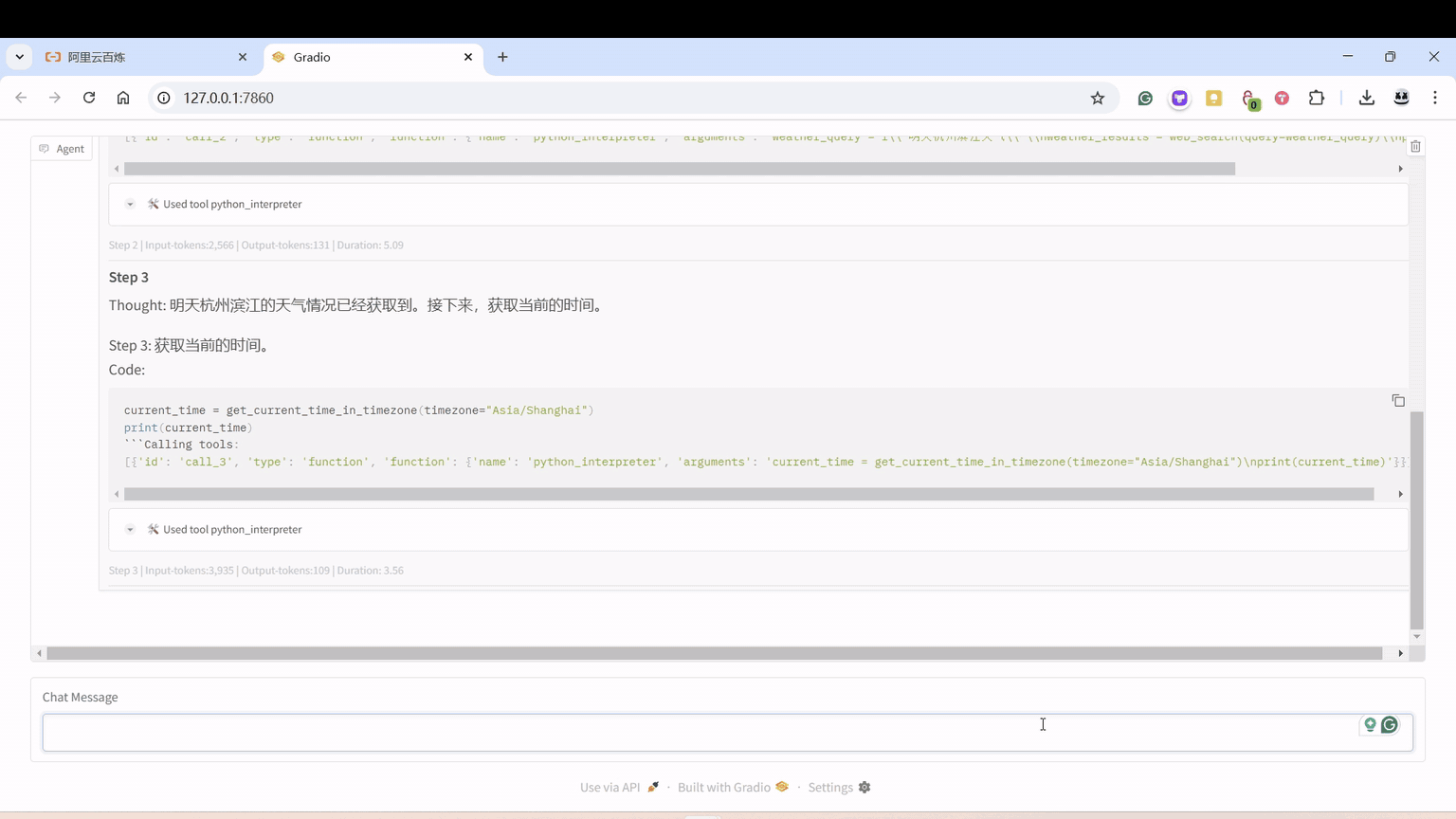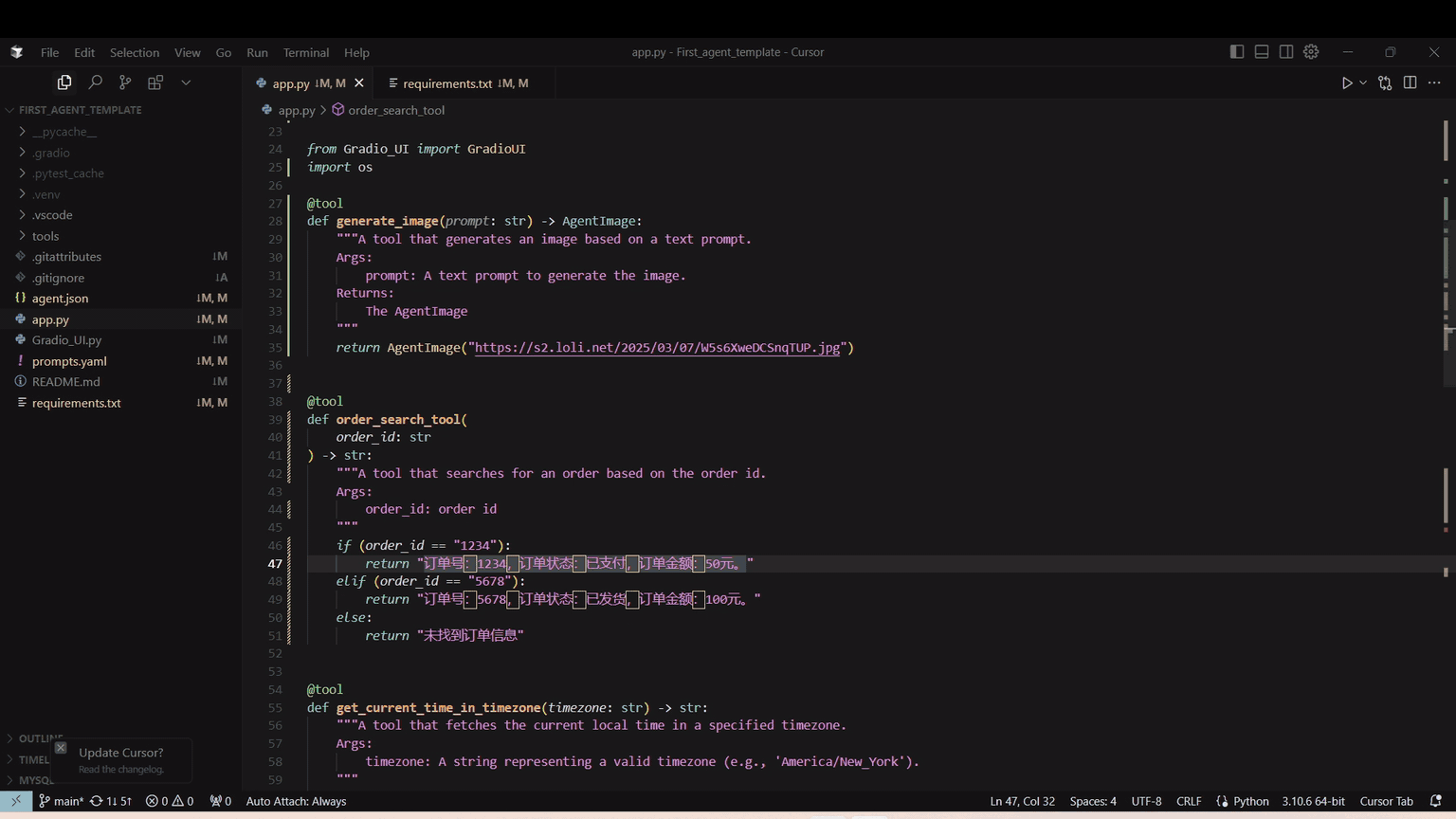
我改了点系统提示词,加了点其他工具。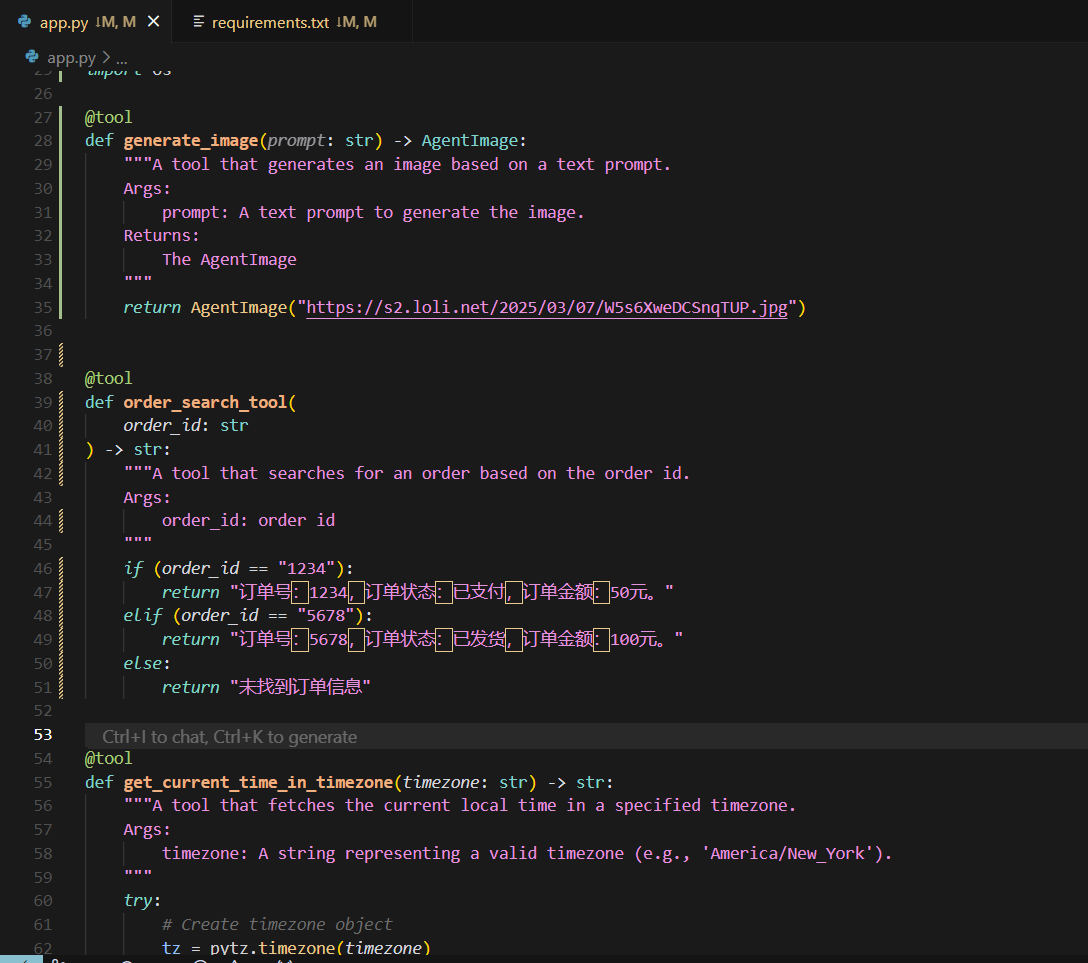
用的是阿里的百炼的 API。